

How to Deploy a MATLAB Deep Learning Model on the AIR-T
Deepwave Digital has included support for MATLAB and the Deep Learning Toolbox using the Open Neural Network Exchange (ONNX) to our artificial intelligence (AI) training-to-deployment workflow toolbox for the AIR-T.
MATLAB is the tool of choice for high-productivity research, development, and analysis across many industries.
The MATLAB Deep Learning Toolbox provides a framework for MATLAB users to design and implement deep neural networks and algorithms.
ONNX is the industry open standard for saving, distributing, and deploying AI and DNN solutions in an interoperatable way.
By including the MATLAB Deep Learning Toolbox and ONNX support in the AIR-T training-to-deployment workflow, users are able to develop for the AIR-T with an industry standard tool which is likely already available. Deploying DNNs for edge-compute radio frequency systems has never been easier for MATLAB users.
Read more below or here is a link to the code-base that runs natively on any AIR-T model.
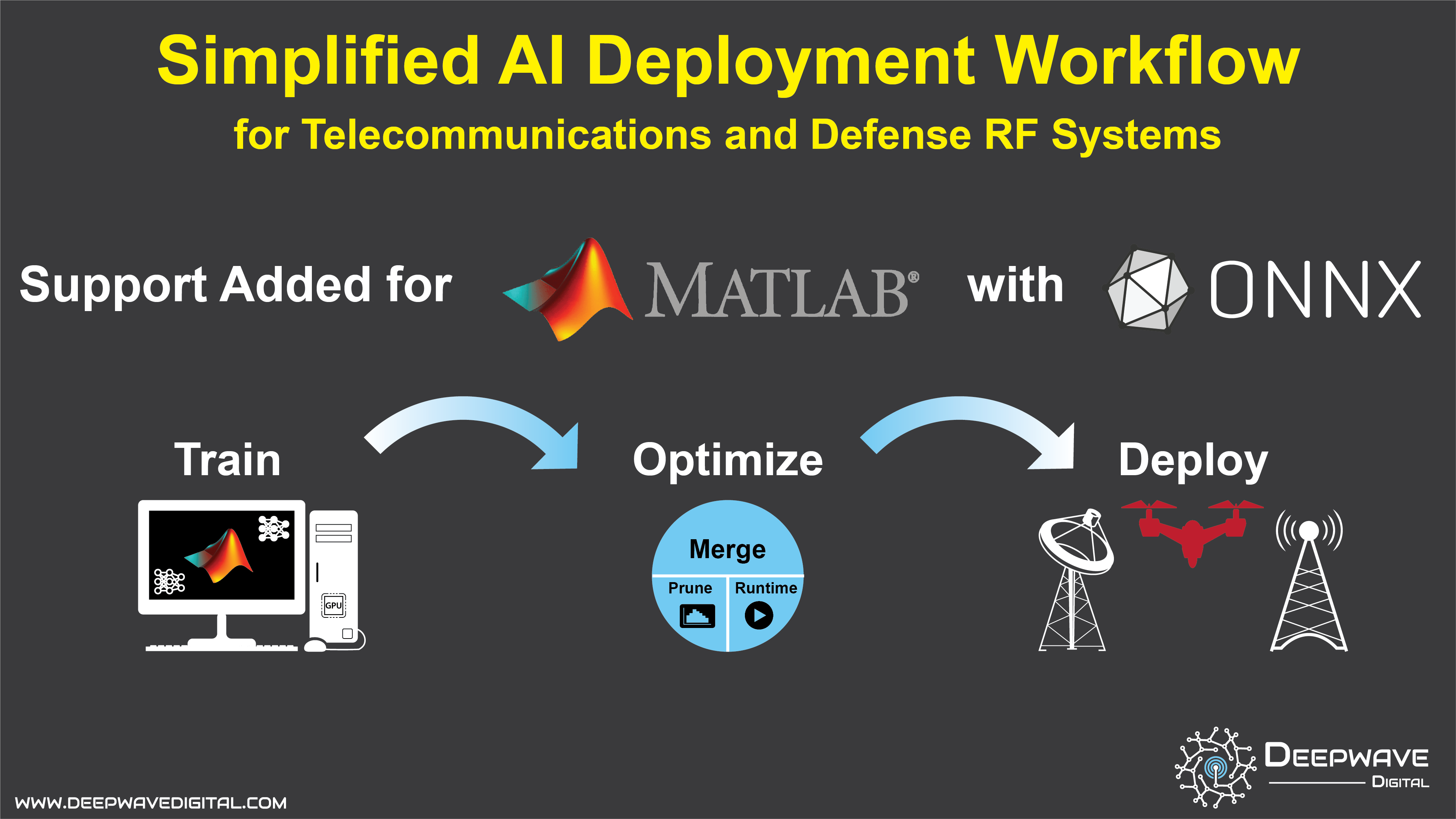
Training to Deployment Workflow for Deepwave's GPU SDR
The figure above outlines the workflow for training, optimizing, and deploying a neural network on the AIR-T.
-
Step 1: Train - To simplify the process we provide an example neural network written in MATLAB that performs a simple mathematical calculation. The MATLAB example is trained for one step and the trained network is exported and saved as an ONNX file.
The Deepwave Digital inference GitHub repository provides the MATLAB example and all of the necessary code and benchmarking tools to guide the user in the training to deployment workflow. The process will be the exact same for any other trained neural network.
-
Step 2: Optimize - Optimize the neural network model ONNX file using NVIDIA's TensorRT, provided with the AIR-T. The output of this step is a PLAN file containing the optimized network for deployment on the AIR-T.
-
Step 3: Deploy - The final step is to deploy the optimized neural network PLAN file on the AIR-T for inference. This AIR-T accomplishes this task by leveraging the GPU and CPU shared memory interface to receive samples from the receiver and feed the neural network using zero-copy, i.e., no device-to-host or host-to device copies are performed. This maximizes the data rate while minimizing the latency.
For more information, check out the open source toolbox here that runs natively on any of the AIR-T Embedded Series models.