

AI for RF and Wireless Systems
Deepwave Digital provides integrated hardware and software solutions that enable the incorporation of artificial intelligence (AI) in radio frequency (RF) and wireless systems. Our technology moves the AI computation engine to the signal edge, reducing network bandwidth, latency, and the task of human-driven analysis.

Hardware Solutions
Deepwave’s hardware technology features the Artificial Intelligence Radio Transceiver (AIR-T), the world’s first software defined radio (SDR) platform designed specifically for RF and wireless deep learning applications.
The AIR-T incorporates an NVIDIA GPU, a Xilinx FPGA, and a multi-core CPU to provide a powerful and flexible SDR. It is offered in various configurations and packaging options for tailoring to your application requirements.

Software Solutions
Deepwave offers various software solutions for exploiting the capabilities of the AIR-T
- AirPack is a framework for building and deploying AI from the ground up on the AIR‑T AirPack
- AirStack Sandbox is a development kit for building custom firmware on the AIR-T’s Xilinx FPGA. AirStack Sandbox
- Our Spectrum Sensing software incorporates DNN technology for classifying signals using the AIR-T. Spectrum Sensing
“Deepwave Digital provides a hardware and software solution, enabling very efficient AI-enhanced, software-defined radios for deep learning applications at the edge, which we believe will enhance our efforts in both autonomy and JADC2.”
"Deepwave’s GPU-based products allow organizations to build AI algorithms in the data center using industry-standard tools and seamlessly deploy AI to the RF edge to reduce deployment times while leveraging the latest AI advancements.”
“With Deepwave Digital's AIR-T product we were able to quickly implement our proprietary Jammer resilient LPI/D wireless waveform and demonstrate its effectiveness to our RIF customer, which helped us to rapidly accomplish the milestone of the challenging project. Now we are accelerating towards demonstrating our deep reinforcement learning solution on AIR-Ts.”
“Deepwave Digital's technology is a key technology in the Key Bridge CBRS solution. Deepwave Digital's AIR-T platform and machine learning technology power the Key Bridge Environmental Sensing Capability and are essential components for our shared spectrum offer.”
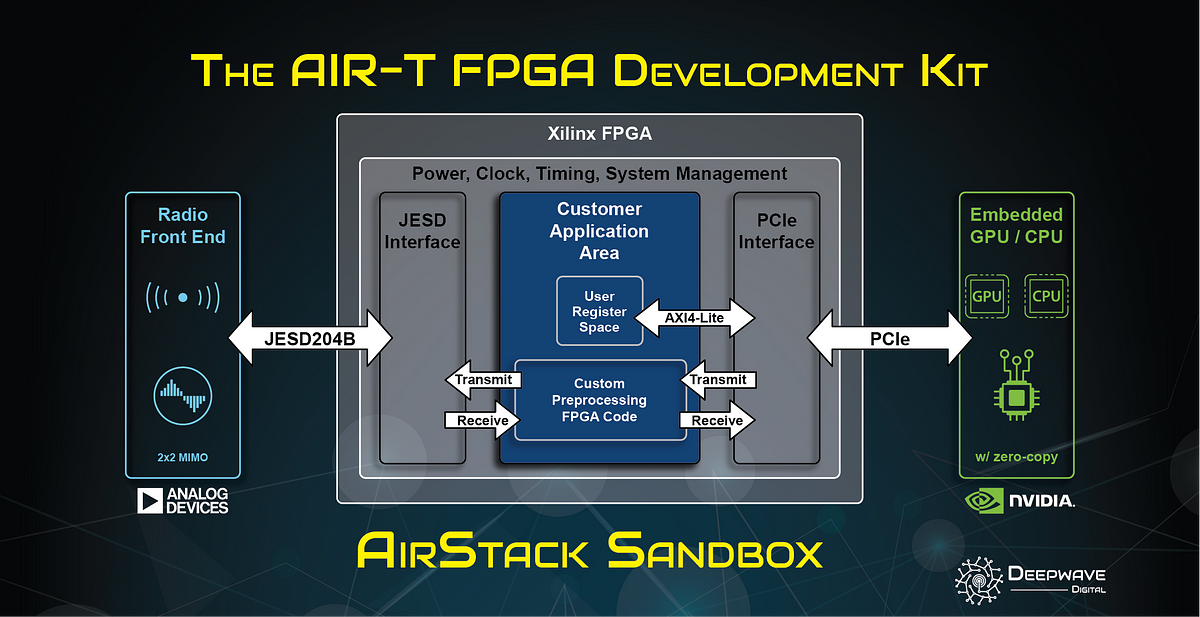



We bring deep learning and AI to RF systems & signals
Interested in the AIR-T and its unlimited solutions? Contact us today!